
New dataset provides researchers new opportunities for analyzing regulatory impacts.
Economic theory alone is incapable of resolving many of the controversies over optimal government regulation; therefore, sound empirical projects must play critical role in helping societies respond effectively to challenges like financial sector reform and climate change. To advance the empirical study of industry regulation, we have developed the first meaningful numerical dataset of U.S. federal regulation, covering a period from 1997 to 2012.
U.S. federal regulation is published in the Code of Federal Regulations (CFR). This publication has led regulatory scholars over the years to use page-counts and word-counts to measure total economy-level regulation, resulting in valuable research at the level of the entire economy. Our new dataset, RegData, evolves this technique by providing more granular data on regulation at the industry level.
How exactly does RegData work? In principle, it simply extends the method used for economy-level regulations: e.g., for each industry, it counts the number of words in the CFR that apply to the industry.
The easy part is getting a list of industries. The North American Industry Classification System (NAICS) provides an exhaustive list of industries. In one version of NAICS, the U.S. economy is divided into approximately 20 industries, whereas in a finer-grained version of NAICS (a six-digit version), the economy is subdivided into over 1,000 industries.
The difficult part is determining whether any particular section of CFR text applies to a given industry. The CFR is not organized in a way that logically maps to a mutually exclusive list of industries. For example, one particularly large component of the CFR is called “Title 40: Protection of Environment,” and the regulations in that title affect a wide variety of industries, from petrochemical manufacturing (NAICS code 32511) to shellfish fishing (NAICS code 114112).
To address the issue of what parts of the CFR apply to specific industries, we developed an algorithm (described more fully in our recent working paper) that assesses the extent to which a paragraph of CFR text applies to a given industry. It works by first creating a list of key words that are associated with each industry, and then seeing how often those words appear in each paragraph of rule text.
In the case of petrochemical manufacturing, unsurprisingly, one of the key words that the algorithm associates with the industry is “petrochemical.” The more times a paragraph has the word “petrochemical” appear in it, the more applicable that paragraph is to petrochemical manufacturing, according to RegData.
Once the algorithm has computed an applicability rating for each industry and each paragraph (within the millions of paragraphs in the CFR), it multiplies the industry’s applicability rating by the number of words in the paragraph. It then totals that figure up across all the paragraphs. That generates a final index of the level of regulation in that industry.
As a further refinement, the algorithm also takes into account how many words in the paragraph are associated with regulations in general, such as “must,” “shall,” and “required.” Put simply, when words like “petrochemical” appear close to words such as “must,” then the section of text is likely to be regulating petrochemicals.
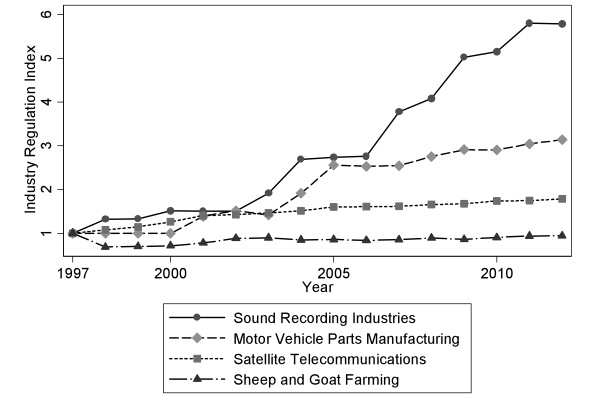
Figure 1 below demonstrates the algorithm’s results for four merely illustrative industries. One can see that with the advent of digital rights management, sound recording industries faced dramatic increases in the level of regulation through the turn of the new millennium, especially compared to the stability of regulation imposed on the more mundane sheep and goat farming industry.
Figure 1: Industry Regulation Index for a Selection of NAICS Four-Digit Industries
RegData allows the researcher to probe deeper on the source of regulation. The text in the CFR is written by the dozens of departments and agencies that comprise the federal government, and, for the most part, the CFR indicates the department or agency that wrote each passage of text. The RegData algorithm can therefore be modified to determine the extent to which a given department or agency regulates a given industry. For example, to what extent does the Department of Labor regulate petrochemical manufacturing?
RegData also offers potentially fresh insight on “hot” debates, such as financial sector reform. In the wake of the Great Recession, two camps emerged. The first camp blamed the financial crisis on unregulated, free markets overcome by greed and shortsightedness, and that camp called for tighter regulation as a solution. The second camp considered excessive government involvement, be it in the form of support for housing loans or post-collapse bailouts, as the source of economic woes, and it saw true liberalization as the solution.
RegData provides researchers with a rich set of tools for assessing the extent and consequences of financial sector regulation. Researchers might gain insights, for example, by looking back across time to see if various indicators of financial market performance – from bankruptcies to new start-ups – correlate with changing levels of regulation.
To be sure, RegData is not a perfect measure of regulation: if you want the “true” measure, you will have to read the entire CFR! Anytime you summarize, you lose important details. But the RegData algorithm is publicly available and adaptable. Similar to the open source community, to maximize the rate at which RegData improves, we subscribe to principles of openness and customizability.
In the often emotional debates over the nature of optimal government intervention, RegData’s imperfections do mean that it can be exploited to support certain agendas. That is another important reason for our openness and customizability policy. We want to avoid the proverbial baby being thrown out with the bathwater by skeptical users. Thus, if some business lobby should try to use RegData to milk favors from the government and opponents grow suspicious of RegData’s algorithm, we would encourage the skeptics to dig deeper, ask questions, and experiment for the benefit of all.
RegData looks to emulate other data collection projects that have facilitated the advancement of economic knowledge. For example, once upon a time, economists could not conduct cross-country comparisons of economic welfare because there were no international GDP datasets. Now, thanks to projects such as the Penn World Table, economists can study the reasons behind international differences in economic development with unprecedented levels of econometric sophistication. Similarly, thanks to the Barro and Lee database, for 30 years now scholars have been able to study international variation in educational attainment.
We aspire to have RegData have much the same impact on the study of industry-level regulation. Rather than being an improvement on previous measurement efforts, RegData is the first true measurement effort beyond mere page counts, meaning that it has the potential to open many new doors.
We hope that many scholars and professionals will find the data useful and will contribute to the further transparent development of new versions of RegData.


This essay is the second of two by the authors explaining why and how they have created their new dataset, RegData.


